Se você precisa inserir muitos dados em uma tabela de um banco de dados, alguns recursos do SGBD (Sistema Gerenciador de Banco de Dados) podem ajudar.
Se você está usando o MySQL (ou MariaDB), aqui vai uma dica valiosa para você não perder tanto tempo na inserção: inserção em lote.
O problema
Eu estava trabalhando com os dados do Censo da Educação Superior 2018 e precisava inserir mais de 12 milhões de alunos em um banco de dados para consultar com mais facilidade.
Então eu pensei: eu não vou inserir 1 a 1, vai levar um dia inteiro. Decidi inserir em lote.
Para inserir o dado em uma tabela do MySQL, o comando é este:
INSERT INTO tabela (campo1, campo2, campo3) values (valor1, valor2, valor3);
Por exemplo:
INSERT INTO cidades(id, nome, estado) values (1, ‘São Paulo’, ‘SP’);
Mas também é possível inserir em lote (batch insert), assim:
INSERT INTO cidades(id, nome, estado) values (1, ‘São Paulo’, ‘SP’), (2, ‘Riberão Preto’, ‘SP’), (3, ‘Guaratinguetá’,’SP’);
Dessa forma, vários registros serão inseridos com um único comando INSERT. Nesse exemplo, o tamanho do lote é 3, pois 3 registros serão inseridos.
Mas qual o tamanho ideal do lote para uma inserção mais rápida?
Antes de inserir os mais de 12 milhões de alunos no banco de dados, eu fiz alguns testes com os dados de cursos (38.255 cursos), para encontrar o melhor tamanho de lote para o meu caso, usando os recursos computacionais que tinha à disposição.
A solução
Eu escrevi um código em Node.js para ler o arquivo CSV e fazer a inserção no MySQL. O código lê arquivos CSV com milhares ou milhões de linhas.
O código está disponível e comentado linha a linha no GitHub.
https://github.com/leandroguarino/censoinep_csv_to_mysql
Os resultados
Para testar a performance de inserção com diferentes tamanhos de lotes, eu utilizei o arquivo CSV de cursos do Censo do INEP, que contém 38.255 cursos de todo o Brasil. Ou seja, os resultados abaixo mostram o tempo para inserir 38.255 registros no MySQL.
O gráfico abaixo mostra o tempo de execução (em milissegundos) para cada tamanho de lote, começando com a inserção de 1 em 1 registro; depois, de 5 em 5; depois, de 10 em 10; assim por diante. Foram testados os seguintes tamanhos de lote: 5, 10, 20, 30, 40, 50, 100, 500, 600, 750, 1000 e 1500.
É possível observar que a inserção de 1 em 1 registro demora muito mais do que a inserção em lote. Além disso, é notório que, à medida que se aumenta a quantidade de registros por lote, o tempo de execução diminui.
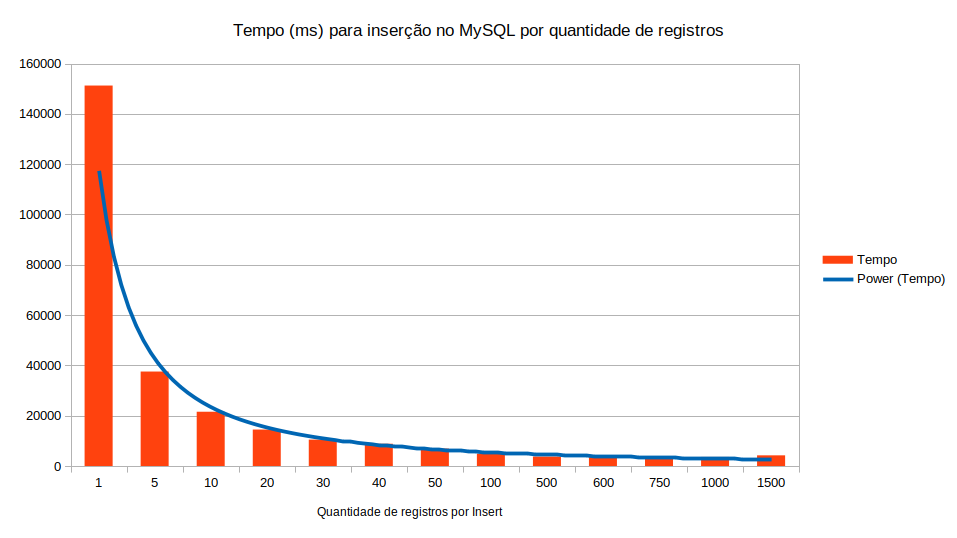
A tabela abaixo detalhe os tempos de execução para cada tamanho de lote.
| Quantidade de registros por Insert | Tempo (ms) |
| 1 | 151253 |
| 5 | 37551 |
| 10 | 21579 |
| 20 | 14510 |
| 30 | 10489 |
| 40 | 8837 |
| 50 | 6933 |
| 100 | 4894 |
| 500 | 3744 |
| 600 | 3557 |
| 750 | 3369 |
| 1000 | 3611 |
| 1500 | 4242 |
O ganho de tempo com a inserção em lote é muito significante. Com lotes de 5 registros, houve uma redução de, aproximadamente, 2 minutos no tempo de execução em relação a inserção de 1 em 1 registro. Com lotes de 750 registros, o tempo caiu de 2min30 (aproximadamente) para cerca de 3 segundos.
No entanto, observe que, a partir da inserção de 1000 registros por vez, o tempo de execução passou a aumentar, provavelmente devido ao tempo necessário para ler e concatenar lotes de 1000 linhas.
Concluindo…
Se você se deparar com um arquivo grande para ler, não se desespere, o código apresentado neste post vai ajudá-lo(a). Após fazer os testes com o arquivo de 38.255 registros, eu fiz a inserção do arquivo de mais de 12 milhões de registros de alunos, e o tempo de execução foi de aproximadamente 20 minutos, com lotes de 1000 registros. Se eu fizesse a inserção de 1 em 1 registro, certamente levaria horas para inserir tudo. Eu não quis pagar para ver 😀
Mas por que fica mais rápido? A cada comando INSERT, o SGBD atualiza os arquivos de índice vinculados à tabela. Portanto, se apenas um registro é inserido a cada INSERT, a atualização dos índices ocorrerá para cada registro. Mas, com a inserção em lotes de 500, por exemplo, a atualização dos índices só ocorre a cada 500 registros. Isso economiza um bom tempo.
Não se pode esquecer que um SGBD manipula arquivos em disco, por isso vale todo esforço para manipular os discos o menor número possível de vezes.
É importante destacar que não significa que é só aumentar o tamanho do lote para reduzir o tempo, porque depende da quantidade de memória disponível e da capacidade de processamento da aplicação em Node.js.
Porém, certamente haverá uma redução significante no tempo se você inserir em lotes de 500 ou 1000 valores.
0 Comments